
We have been struggling with many deadlocks in an old project that started getting busier during working hours. This project was initially built quickly to solve a small problem in stock operation. Over the last three years, a lot of code and processes have been added to the platform. As a result, we have a big platform with a very unstable base of code structure. This is one of the common issues where we see projects were developed without any longer-term plan.
So, what is deadlocks?
SQL Server deadlocks occur when two processes/queries attempt to access the same data, but each query has already locked the data that the other query needs. In simple terms, it is a lock that takes you to the dead end. While query optimization can improve the speed and efficiency of queries, it’s crucial to understand the root cause of deadlocks and how to prevent them. A deadlock happens when two or more tasks permanently block each other, with each task holding a lock on a resource that the other tasks are trying to acquire.
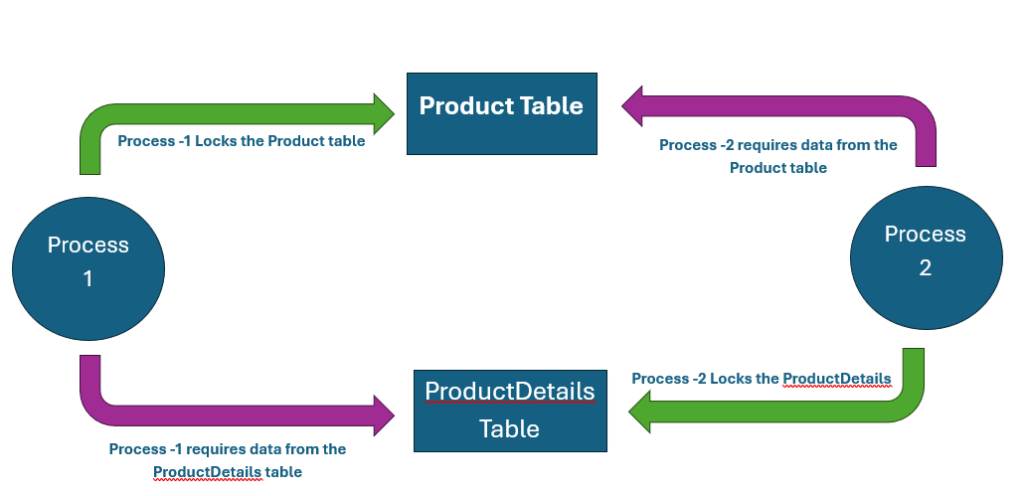
For example, Process-1 needs to modify data in the Product table, which also requires reading data from the ProductDetails table. So, Process-1 puts a lock in the Product table and requests data from the ProductDetails table. At the same time, Process-2 needs to modify data in the ProductDetails table, which also requires reading data from the Product table. So, Process-2 puts a lock in the ProductDetails table and requests data from the Product table.
At this point neither process can finish because they are both waiting on locked resources. i.e. they are deadlocked. One of them must be killed to allow either of them to finish. SQL decides which is the “least expensive process to kill” and it becomes the Deadlock victim.
Let’s not confuse deadlock with Blocking.
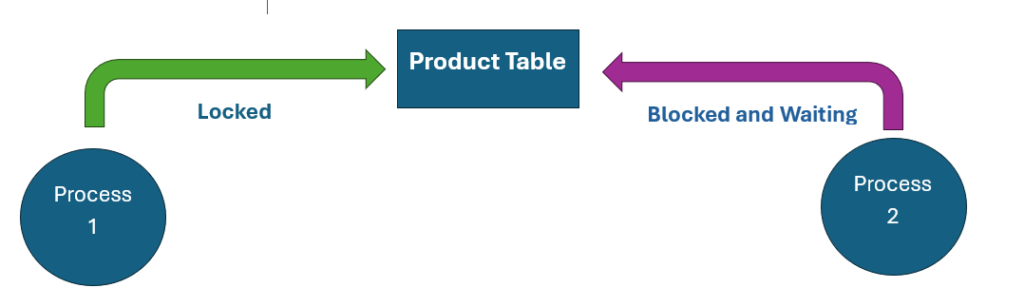
Although it’s based on the same principles, blocking is much simpler than deadlock. Blocking happens when two or more processes need access to the same resource. In Microsoft SQL Server, only one process can use a resource at any given time. If the first process is already using (or locking) the resource, the second process is blocked from accessing it. SQL Server will then make the second process wait until the first process has completed its task.
What was happening in our case
We have many SQL jobs that frequently get product feeds from our supplier and update the product, product details table and a few other tables. During the process, the SQL job locks the Product table to make necessary updates and request details of the product from the ProductDetails table. This process takes a long time due to the large volume of data the SQL job processes. At the same time, if anyone in our team uses our internal web applications to update any product details that require updating the ProductDetails table and getting data from the product table, the web application becomes the victim of the deadlock. Also, the team always complains that the product update process takes a long to time complete even they do not get the deadlock.
So what we have done to resolve the issue
We have identified that our platform is a victim of both blocking and deadlock. So, we have taken the following steps to improve the issue.
Create a separate temporary Product table to hold the products from all SQL jobs. This will free the main Product table for the web applications.
Put multiple similar SQL jobs under one job but in steps. Set to run the following step once the current step is completed and succeeds. The last step is to update the main Product table from the temp Product table.
In our case it is important to allow our web application to get the priority. So we set SET DEADLOCK_PRIORITY LOW for the query behind the SQL job. By default SQL set SET DEADLOCK_PRIORITY NORMAL for all queries so the web application query will have the priority and SQL Job will be the victim of the deadlock.
Use ” WITH (NOLOCK)” for the select queries, which is equivalent to READ UNCOMMITTED
Ensure enough Index and tune the transactional code to make sure the query runs faster.
Deadlock code example
To experience the deadlock, you can use the code below.
Creating two tables and adding some sample data
CREATE TABLE ##Product (
ProductId INT IDENTITY,
ProductName VARCHAR(16),
ProductCode VARCHAR(16)
)
GO
INSERT INTO ##Product (ProductName, ProductCode)
VALUES ('iPhone', '123'), ('iPad', '124')
GO
CREATE TABLE ##Supplier(
SupplierId INT IDENTITY,
SupplierName VARCHAR(64),
SupplierEmail VARCHAR(64)
)
GO
INSERT INTO ##Supplier (SupplierName, SupplierEmail)
VALUES ('Apple', '222-555-6666'), ('Samsung', '888-568-1234')
GO
Now, Open two separate query windows in SSMS. In one window, enter the code for session 1, and in the other, enter the code for session 2. Execute the steps in each session alternately, switching between the two query windows as needed. You’ll notice that each transaction holds a lock on a resource that the other transaction is also trying to access.
-- Step 1 -- -- Run in Session 1 --
BEGIN TRAN;
UPDATE ##Product SET ProductName = 'Apple Watch'
WHERE ProductId = 1
-- Step 2 -- -- Run in Session 2 --
BEGIN TRAN;
UPDATE ##Supplier SET SupplierEmail = N't@t.com'
WHERE SupplierId = 1
-- Step 3 -- -- Run in Session 1 --
UPDATE ##Supplier SET SupplierEmail = N's@s.com'
WHERE SupplierId = 1
-- Step 4 -- -- Run in Session 2 --
UPDATE ##Product SET ProductCode = '234'
WHERE ProductId = 1
And You will get deadlock.
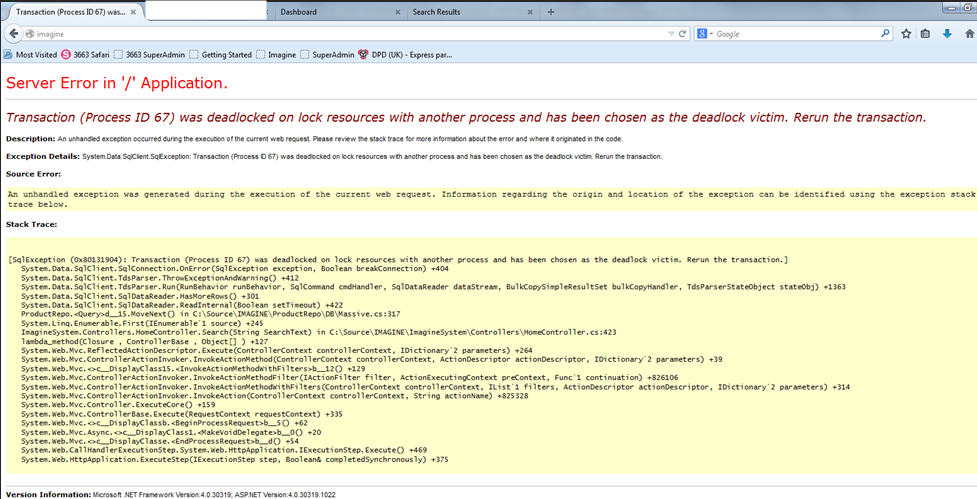
Msg 1205, Level 13, State 45, Line 7
Transaction (Process ID 70) was deadlocked on lock resources with another process and has been chosen as the deadlock victim. Rerun the transaction.